跨境电商 NodeJS BFF 集群耗时问题定位与优化之旅
- 本文介绍了如何在一个真实业务服务中,通过火焰图等工具,定位和解决耗时问题。抽丝剥茧,遇水搭桥,最终也取得了非常好的效果。
- 本文介绍的BFF集群是我工作这么多年来觉得,为数不多真正业务、后端、前端都认可并且真有用的BFF服务,因为涉及到跨境和合规,所以需要BFF来提供「聚合」和「代理」的功能,解决大陆前端请求多次海外服务的链路耗时问题。
背景
在2023 Q3(还在字节跳动的时候),被调去支援Global Selling项目(后面也称S业务)。根据原团队同学的调研结果文档发现整个跨境电商的 BFF 服务层在调用rpc接口时,存在通用的接口耗时过长问题,rpc本身耗时与nodejs端耗时达到了惊人的10:1 。
当时和原团队同学沟通后得知,此问题在长达一个Q的时间里持续影响着S业务,并且随着美英开国,对用户体验的影响日趋严重。因此专门抽出时间与相关同学一起进行定位和解决。
收益效果
如果不想看下面的定位和分析过程,可以直接看这里的收益。效果比较明显。
下面截图是压测并发数4 5分钟,同时打CPU profile的记录,运行120s,查看整体的js耗时情况
CPU Profile 整体降低 26%
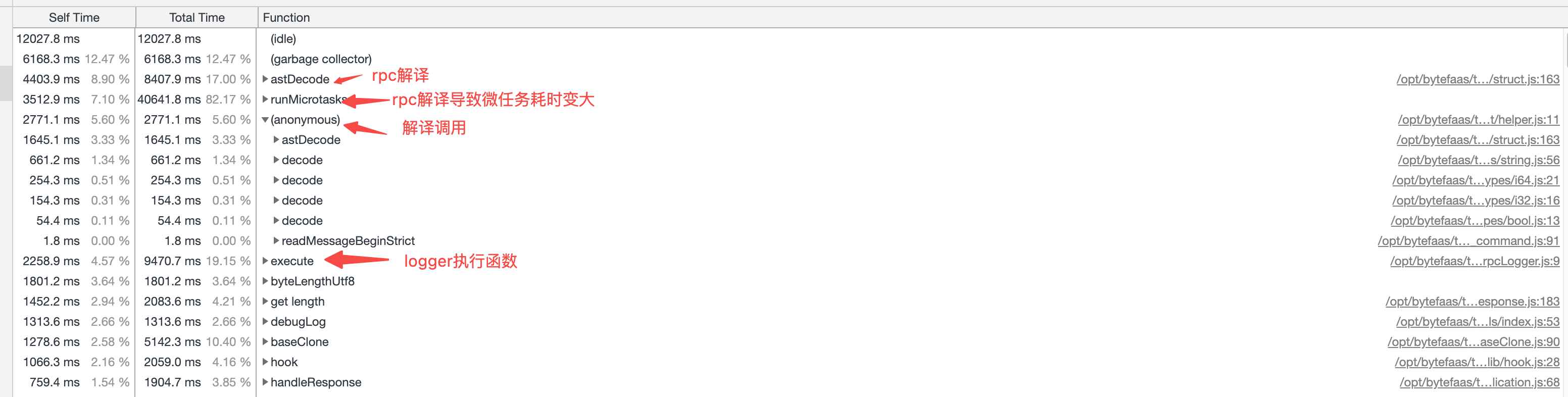
生产环境:
- rpc调⽤和logger⽇志都占⽤了极⼤的cpu
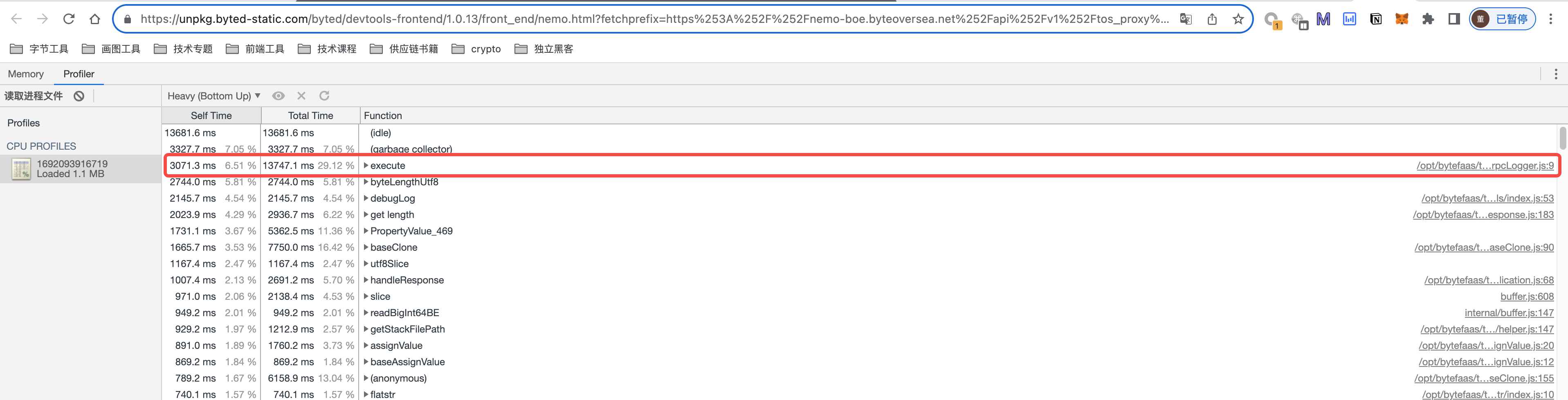
优化1: 开启rpc预编译的效果
- 通过rpc预编译避免了decode,从⽽减少了microtask的耗时,不会再出现nodejs侧rpc库
onData⽅法触发过久的问题 - 去掉后,excuete⽅法耗时排名第⼀
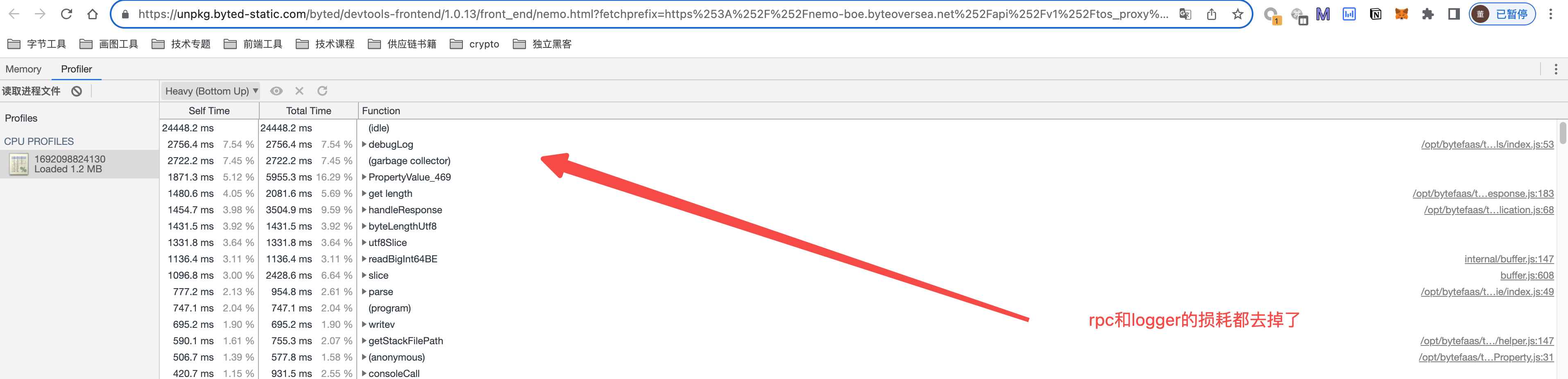
优化2(最终效果):开启rpc预编译+关闭全量logger
- excute⽅法耗时降下来,整体cpu资源占⽤减少26%
Nodejs侧rpc调用时间与rpc时间的比降低到 1:1
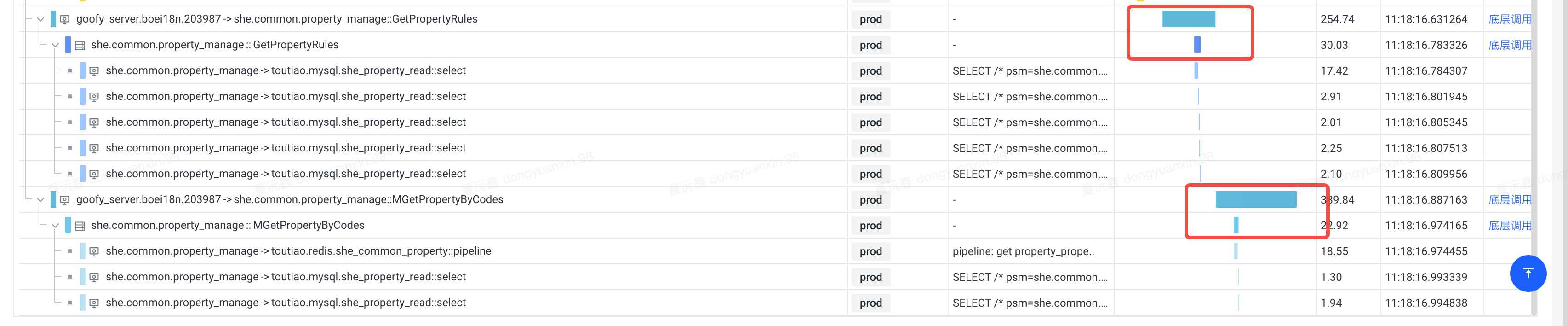
生产环境:
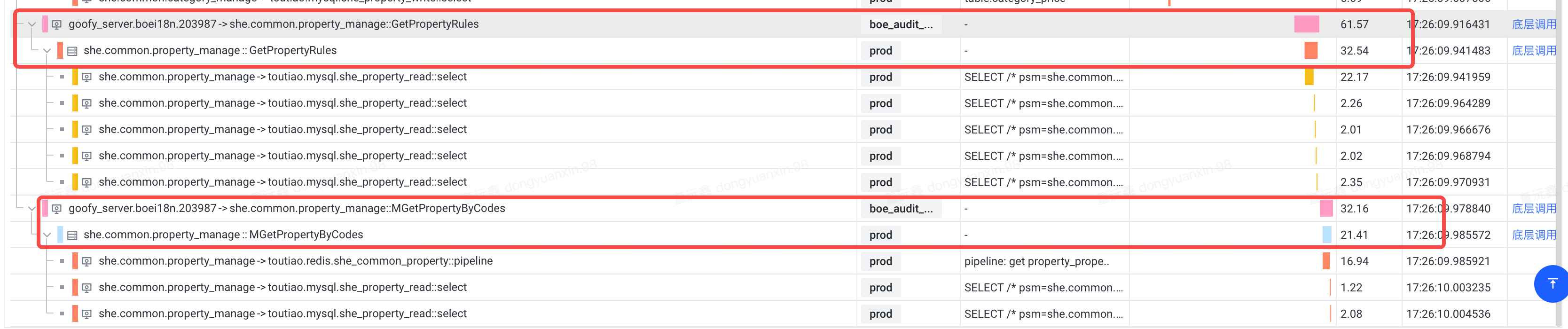
- 从拓扑链路上能看到,红框中是nodejsbff对rpc的调⽤,bff侧是398ms,rpc耗时22ms,⽐例达到惊⼈的10:1
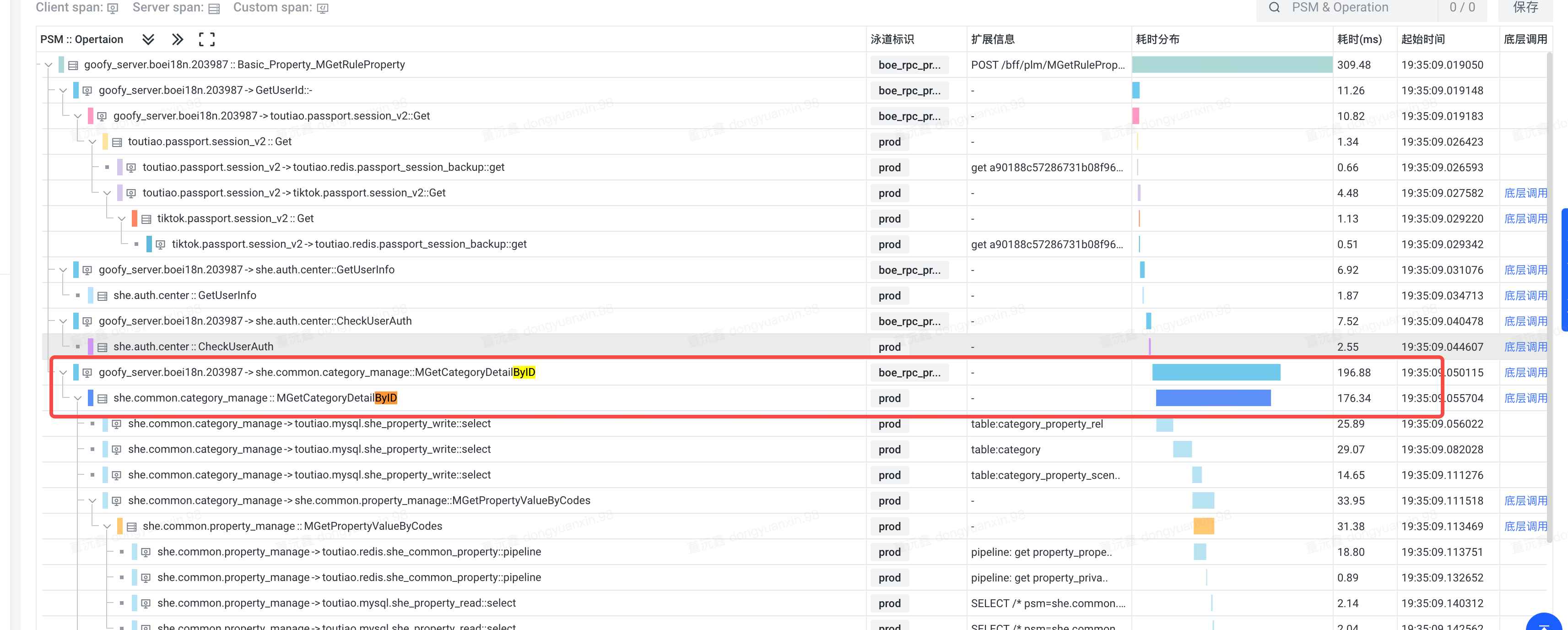
优化1:开启rpc预编译的效果
- 和第一张图相比,bff时间:rpc时间从10:1降低到了1:1

- 但是bff这里还有一些损耗,虽然没那么大了
优化2(最终效果):开启rpc预编译+关闭全量logger
- bff时间:rpc时间稳定在1:1,除了网络,几乎没有损耗了
相同并发下QPS提高2倍,耗时降低60%
控制变量:同样使用并发量4进行压测,观察单机服务的qps。
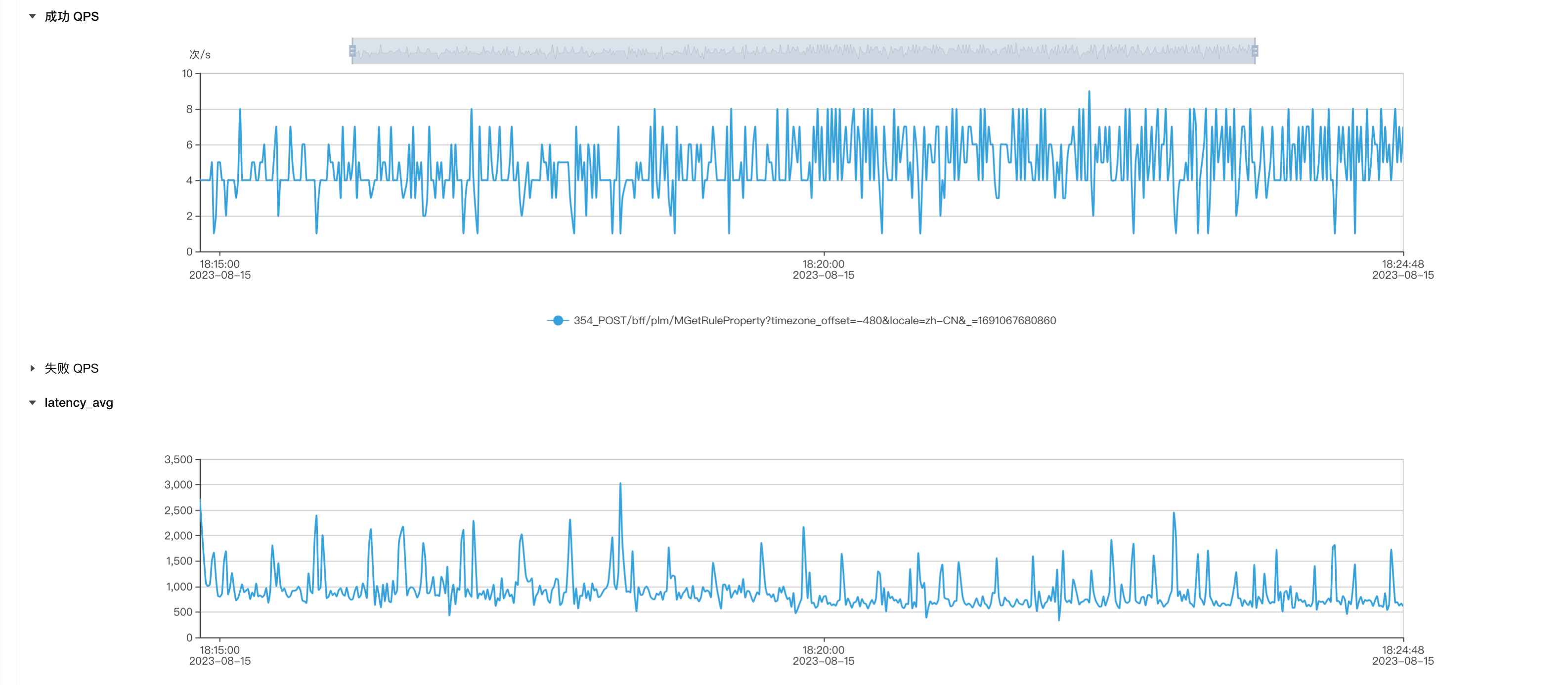
生产环境:平均qps4-6,平均耗时在800ms左右
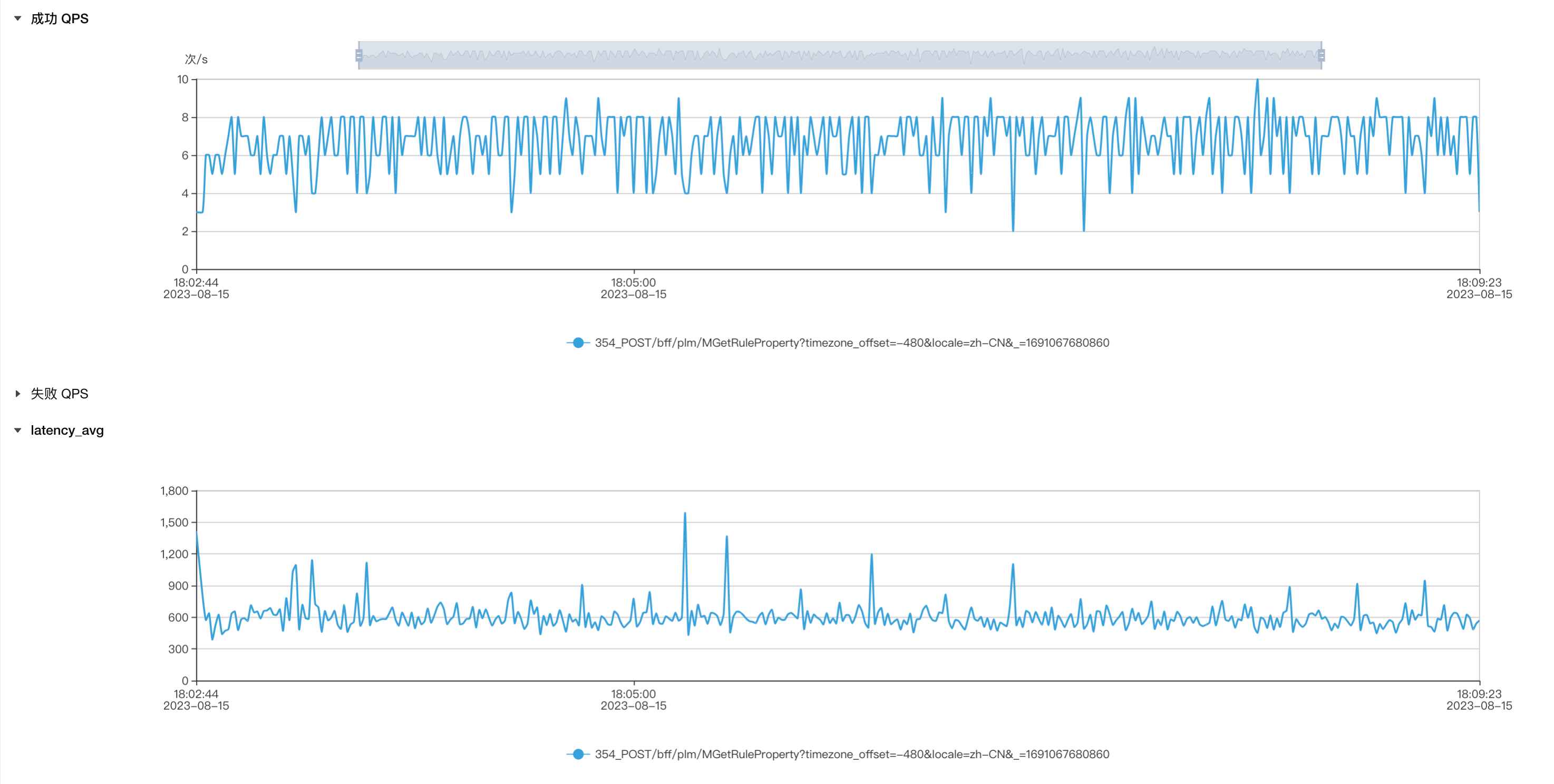
优化1(开启预编译):平均qps在6-8,平均耗时在600ms左右
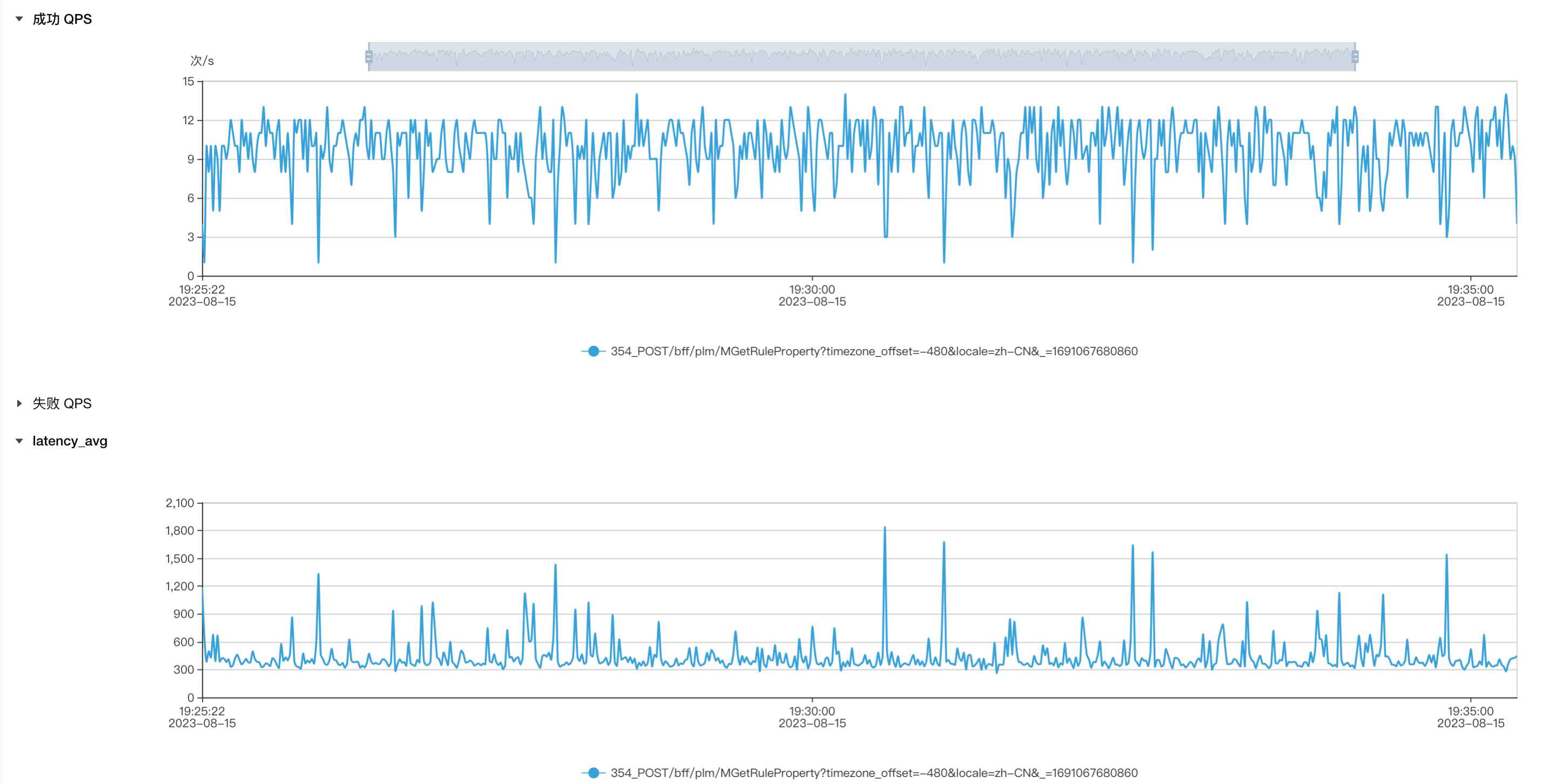
优化2:平均qps在10左右,耗时350ms左右
NodeJS 服务排查步骤
古人云:工欲善其事,必先利其器。
在排查nodejs服务的性能问题、OOM问题以及验证优化效果时,均需要从监控入手。结合公司内的一些成熟工具,我们总结的步骤如下:
- 监控观察:参考 可观测性 / Logger、Metrics、Tracing (内部分布式日志平台、监控平台)提供的工具。
- 通过「链路拓扑」查看请求链路上各节点的的耗时
- 通过 argos,查看服务整体的qps、接口耗时等性能指标
- 进程观察:
- 通过 Nemo(内部 NodeJS 服务观测工具)打出CPU Profiler,观察具体的函数耗时
- 通过 Nemo打出内存快照,来定位排查OOM问题
- 本地复现:
- 遇到问题时,大概猜测原因,然后尝试在本地进行复现。可以配合 autocannon 等本地压测工具,来进行压测
- 需要排除网络问题干扰,可以借助一些内部的云IDE平台和后端rpc服务拉齐网络环境,方便调试和定位
- 压测复现:
- 从主分支切测试分支,部署一个boe泳道进行压测,不能影响线上
- 使用 Perf 压测中台(内部平台) 进行压测,然后再通过「监控观察」和「进程观察」观察问题是否复现
- 效果验证:
- 在确定问题后,快速修改一份代码(不是最终方案),然后部署到 BOE 泳道
- 使用 Perf 压测中台(内部平台) 进行压测,然后再通过「监控观察」和「进程观察」分析优化效果
问题归纳
RPC未开启「预编译」导致astDecode和runMicroTasks耗时过多
现象描述
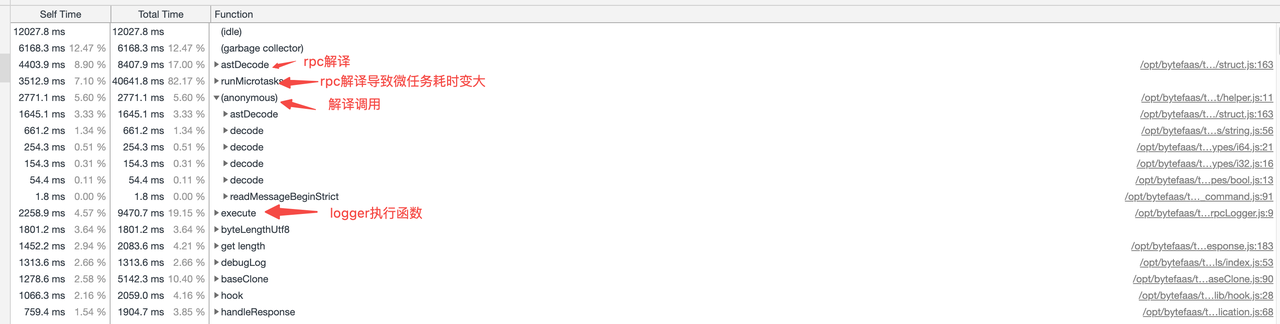
通过nemo对现网服务打快照时可以发现, astDecode 和 runMicroTasks 方法占用cpu较多。
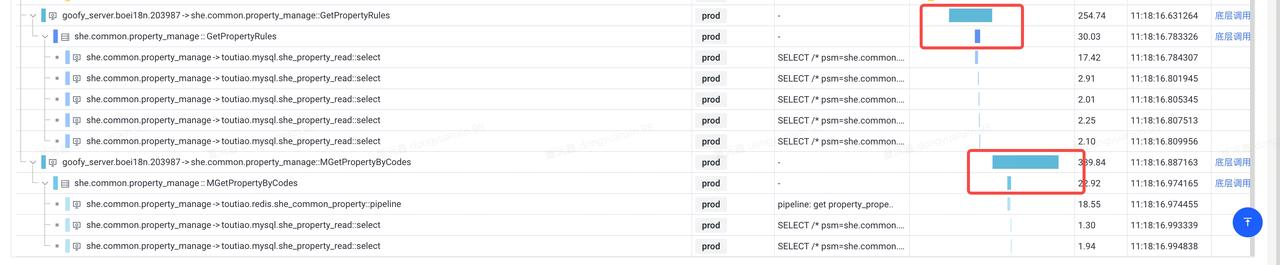
通过拓扑链路分析,能看出来底层rpc耗时只有23ms,而nodejs服务里面的rpc调用耗时达到了390ms。多出来很多无效时间。
问题分析
通过第一张cpu profiler图的方法对应代码路径进行定位,发现是 @byted-service/rpc 的内置方法。通过函数名以及内部的运行逻辑,大概能猜出来是在对 IDL 进行 AST 解析时,耗时比较大。
当时找了 NodeJS Infra 的同学帮忙定位,确实是 AST 解析导致的耗时过多(问题群已解散,找不到截图了 )。可以通过打开「预编译」配置来优化。
解决方案
预编译
什么是预编译呢?
众所周知,rpc调用和http调用不同,需要根据 thrift / protobuf 的文件,来按照字节码一位位地进行解析,才能理解服务和服务之间的包体。那么按照字节码一位位解析的过程中,本质上就是解析 thrift/ protobuf 为 AST,并且将AST转换成DataTypes的过程
这个过程分为2种:
- 不开启预编译:序列化一个
DataType,再调用 DataType 上的encode之类的方法将数据写入到Buffer对象中。此时,如果DataType还有嵌套子DataType(对应thrift的struct),那么就会先递归序列化子DataType以及调用其上的encode方法。 - 开启预编译:直接把这坨动态逻辑预先生成为性能更高的代码。
下面是个示例对比:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
// 未开启预编译
function encode(struct) {
if (struct.childs.length) {
struct.childs.forEach(c => {
c.encode(xxx); // writeBuffer(xxx)
});
}
struct.encode(xxx); // writeBuffer
}
// 开启预编译
function encode() {
writeBuffer(xxx) // child 1
writeBuffer(xxx) // child 2
writeBuffer(xxx) // child 3
writeBuffer(xxx) // struct
}
如果想了解更多预编译的知识,可以参考:《深入浅出 Node RPC》、《RPC 优化方案 - 预编译》
因此,开启gulu rpc插件配置中的预编译选项即可: 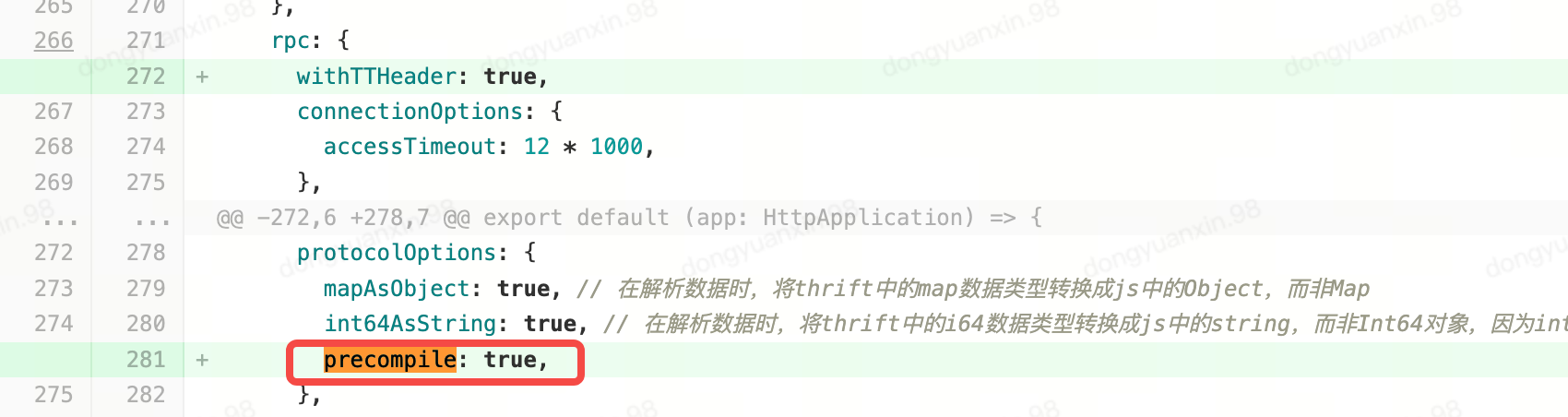
在gulux新版本中,预编译是默认开启的。而S业务的BFF使用的是gulu老版本,需要手动开启。
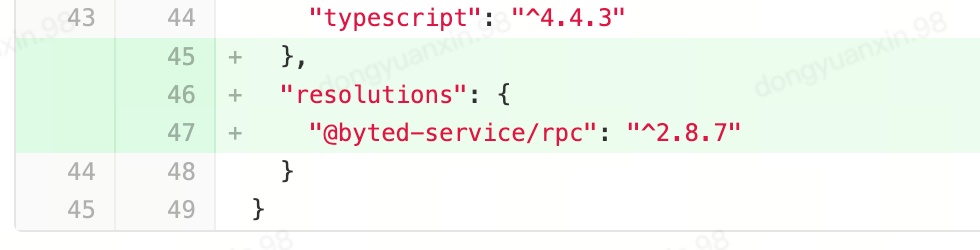
在开启后,我们发现依然不生效。经过排查是底层的 @byted-service/rpc 版本过低,需要升级到 ^2.8.7 以上才可以。
由于S业务的gulu版本较老,并且使用了大仓的架构,所以通过修改 package.json 的 resolution字段来修改深层依赖版本。代码如下:
日志打印导致CPU过高
现象描述
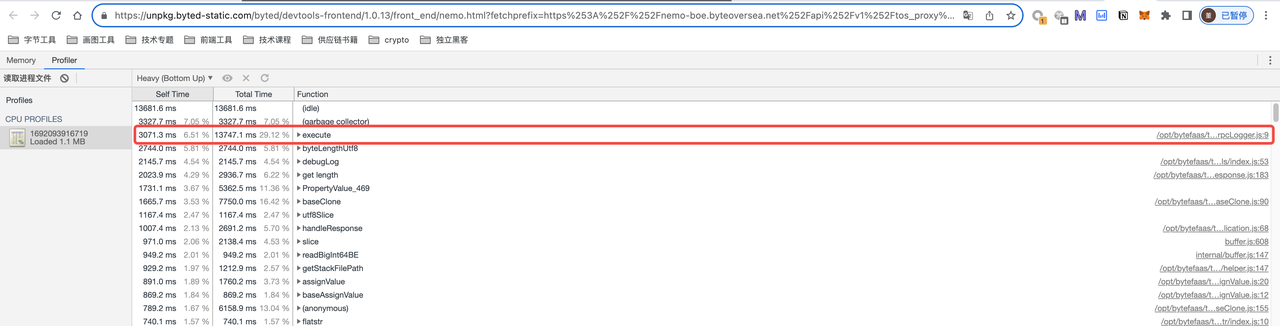
从nemo的cpu profiler上来看,logger插件的 execute 插件占用了大量的cpu。
同时,从内部的告警来看,当一个接口里面调用的rpc接口返回数据比较大时(比如PLM系统的选品池列表接口),数据达到10mb,此时调用次数过多就会导致OOM(服务崩溃了)
问题分析
日志体积
目前使用 JSON.stringify 全量转换数据,其中遍历了6层,对里面超出1000长度的字符串做了裁剪。
问题是目前数据是整体过大,单个大字符串场景比较少。并且在logger打印过程中,会存在多次值拷贝,导致字符串内存占用膨胀。多次OOM问题都是打印体积过大导致的。并且日志库底层调用的是 gulu 提供的 logger.info() 方法。每次打印日志时,底层都会定时将日志收集起来,并且上报给 Argos metrics 等远端服务,存在网络I/O的消耗。
如果上报的日志提及过大不进行控制,对服务的网络吞吐能力有影响,也会影响线上日志的刷新。
治理思路:利用 util.inspect 替换 JSON.stringfy() ,控制复杂对象序列化后的字符串长度(日志长度)。
文件I/O
在http请求进入/返回和rpc请求发送/返回都做了日志打印,并且 gulu 提供的 logger.info() 方法也会往本地文件写入日志,占用文件IO:
- Console:把日志输出到控制台,默认仅本地生效
- Filelog:把日志输出到本地文件
当日志体积大或者日志方法频繁调用时,对性能有一定影响。
治理思路:对于大多数日志场景而言,我们都是在argos上对日志数据进行消费,极少有上实例上直接查询日志,并且实例上的日志会因为机器容量问题定期清理,可靠性不高,可以考虑关闭
无效打印
由于NodeJS服务和前端页面不同,在中心化的服务中,大量打印非常影响性能。 并且大多数日志对于排查问题而言没有帮助,属于无用日志,比如log会打印所有header信息,用户登录信息会打印所有用户权限,transferProperty会打印所有转换用的数据等,降低排查效率。
并且BFF中出现了直接使用 console.log 的地方。
治理思路:提供统一的安全打印函数,函数内部调用 gulu 的 logger 方法;通过 eslint 配置,在中心化的nodejs 服务中禁用 console.log 方法。
解决方案
JSON 序列化
使用 utils.inspect() 方法替换 JSON.stringfy() ,优化日志体积大小。utils.inspect() 函数配置如下:
- 整体日志长度限制在1000个字符
- 对于深层对象:
- 将打印深度限制在 5,不会一直递归到最底层。
- 对于字符串类型的字段,长度限制在30个字符
- 对于数组类型的字段,长度限制在 5
(以上限制,可以在上线观察一段时间后,再进行调整)
代码示例如下:
1
2
3
4
5
6
7
8
9
const genLog = (obj: any) =>
util
.inspect(obj, {
maxStringLength: 30,
maxArrayLength: 5,
depth: 5,
breakLength: Infinity,
})
.substring(0, 1000);
通用打印函数
- 封装通用打印函数 sLog 。代码实现上,调用前面封装的 genLog 进行json序列化,调用gulu 的 logger 方法进行打印。并且将其挂入到 gulu 的上下文中。
- rpc-forward、gulus-trace等插件内部,使用 sLog 方法进行打印,控制打印日志体积,避免console.log 调用导致的阻塞。
- 修改BFF的配置,添加 eslint 的 no-console 规则,禁用上层业务直接调用 console.log
sLog 放在 app/extension/context.ts 中,代码示例如下:
1
2
3
4
5
6
// app: HttpApplication
export default (_app: HttpApplication) => ({
sLog(this: HttpContext, obj: any, prefix = '') {
this.logger.info(prefix + genLog(obj));
},
});
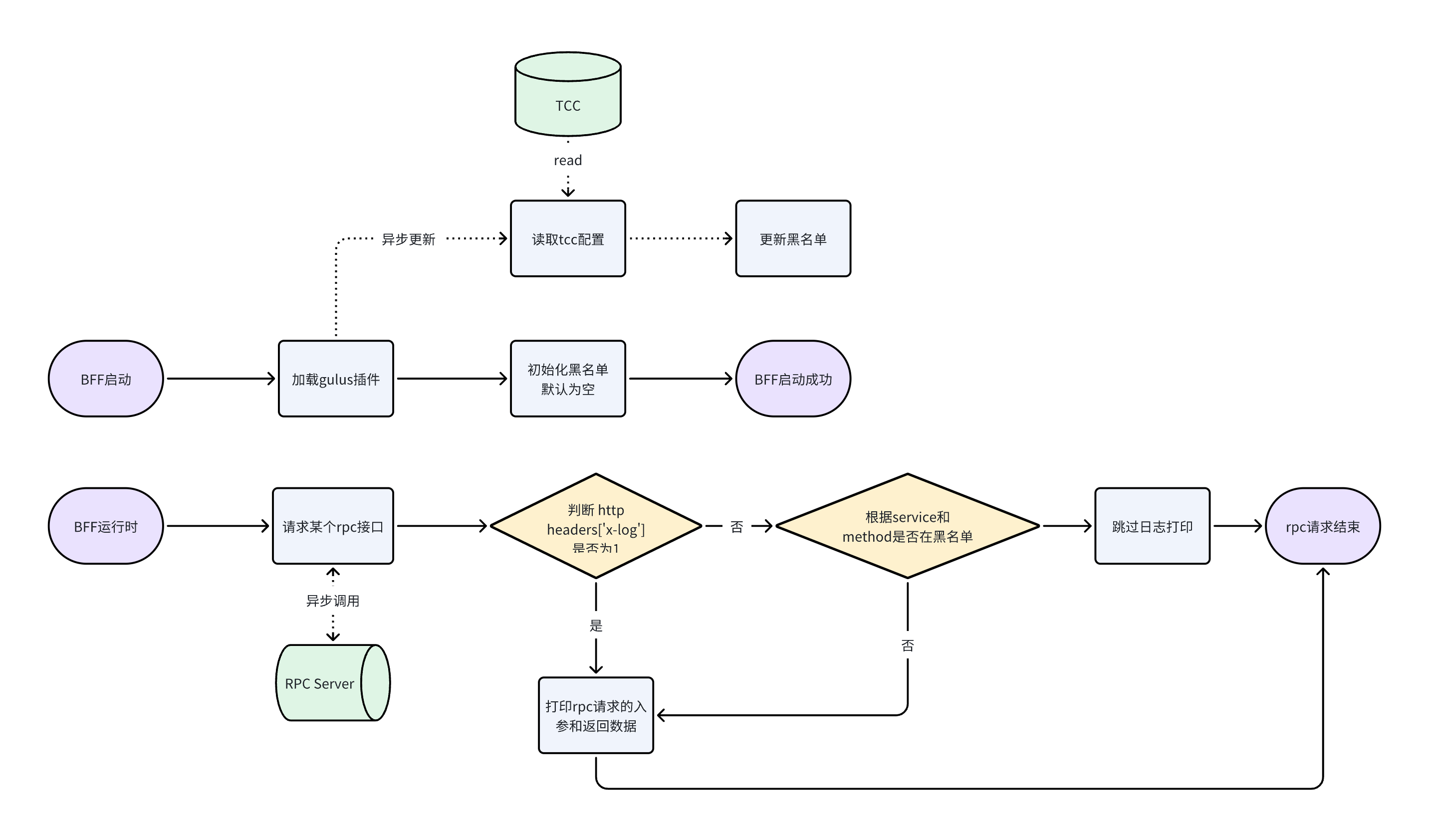
黑名单机制
BFF中,不论是rpc转发还是rpc调用拼装业务逻辑,由于gulus-trace的存在,每次rpc请求前后,都会进行日志打印;而在大多数bff接口中,都会调用3-5次rpc请求。
除了通过前面的「JSON序列化」以及「通用打印函数」优化序列化性能和日志大小,还可以在某些接口中关闭打印,直接从源头切断无效日志的输出。
考虑到不影响现网的rpc调用日志打印,以及配置白名单rpc接口过多,因此使用「黑名单机制」。为了方便研发同学调试或者定位某个用户的问题,支持将 HTTP Headers 里的 x-log 字段设置为 1 来打开一次请求链路上的全量日志。
考虑线上问题出现时,需要排查日志来来定位问题,此时需要快速调整黑名单,而不是重新修改代码进行发版。所以需要上「TCC」(内部平台,一个配置下发的平台)。
整体设计图如下:
代码示例如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
import { ClientContext, ClientMiddleware } from '@gulu/rpc';
// rpc接口中间件,在rpc接口请求返回的时候打出log
export const rpcLogger: ClientMiddleware = {
name: 'rpc-logger',
// 中间件执行
async execute(ctx, next) {
const logger = ctx?.refContext?.sLog?.bind?.(ctx?.refContext);
const loggerConfig = ctx?.refContext?.app?.config?.guluS?.logger;
// 判断
const needLog = checklog(loggerConfig, ctx);
if (needLog) {
try {
const requestLogs = {
// ...
};
logger(requestLogs, '[GULUS LOGGER] rpc request');
} catch (_e) {
logger('rpc log run error', _e);
}
}
await next();
if (needLog) {
try {
const responseLogs = {
// ...
};
logger(responseLogs, '[GULUS LOGGER] rpc response', responseLogs);
} catch (_e) {}
}
}
};
总结
- 善用公司内的各类 Node.js 工具分析问题,而不是凭空猜测
- 定位问题拉 Node.js Oncall 时,给出详细的问题描述以及监控截图,减少沟通成本
- Node.js 服务和前端页面不一样,中心化服务对性能要求更高